Als Alternative zu IOmeter kann auch ein aktuelles Microsoft-Tool zum Einsatz kommen, das Performance-Tests von lokalen Festplatten und SSDs (DAS), LUNs einer SAN, Storage Spaces oder SMB Freigaben ermöglicht: » DiskSPD (https://aka.ms/DiskSpd)
Als Alternative zu IOmeter kann auch ein aktuelles Microsoft-Tool zum Einsatz kommen, das Performance-Tests von lokalen Festplatten und SSDs (DAS), LUNs einer SAN, Storage Spaces oder SMB Freigaben ermöglicht: » DiskSPD (https://aka.ms/DiskSpd)
Dabei läuft das Tool auf 32-Bit, 64-Bit und ARM Versionen von Windows sowohl auf physikalischen Servern als auch innerhalb einer VM. Das kommandozeilenbasierte DiskSPD („disk speed“) kann ähnlich wie IOmeter verteilte random I/Os erzeugen und messen, ebenso können eigene Workloads definiert werden.
DiskSpd ist open source (MIT License); das Projekt findet man auf GitHub:
» GitHub.com/Microsoft/Diskspd
Das Tool bietet eine Fülle von Möglichkeiten Parameter für einen Workload zu definieren. Weiterführende Informationen dazu findet man in der Dokumentation auf GitHub (» DOC und » PDF Format).
Im Gegensatz zu IOmeter, dessen Entwicklung seit 2006 weitgehend stagniert, und dem abgekündigten SQLIO wird DiskSPD derzeit aktiv weiterentwickelt und zeigt mit VMfleet auch Workloads für den kommenden Windows Server 2016. Diskspd läuft auch unter der Windows Server 2016 deployment option Nano Server.
Wer ein neues Storage-System in der eigenen Umgebung auf Herz und Nieren hinsichtlich Bandbreite, Durchsatz und IOPS mit verschiedenen Lastprofilen testen möchte, für den stellt DiskSPD eine gute Alternative zu IOmeter, IOzone oder Vdbench dar.
Stay tuned,
N.Own
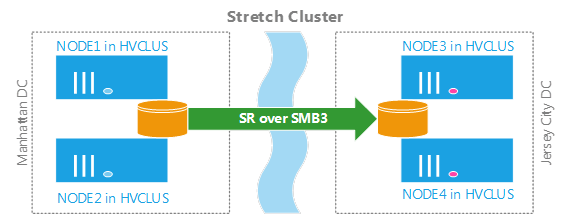
 Mit der Ignite Konferenz wurde die zweite Beta von Windows Server 2016 (Windows Server vNext) als Technical Preview 2 veröffentlicht.
Mit der Ignite Konferenz wurde die zweite Beta von Windows Server 2016 (Windows Server vNext) als Technical Preview 2 veröffentlicht. Für die kürzlich erschienene Windows Server Technical Preview (Windows vNext) gibt es auch neue Features für das Clustering:
Für die kürzlich erschienene Windows Server Technical Preview (Windows vNext) gibt es auch neue Features für das Clustering: